苹果公司最新研究报告指出,大语言模型可以通过分析音频和运动数据的文本描述来精准识别用户活动。这项技术未来可能应用于Apple Watch上。研究名为“后期多模态传感器融合”,结合了大语言模型的推理能力和传统传感器数据,在传感器信息不足的情况下也能准确判断用户的活动。
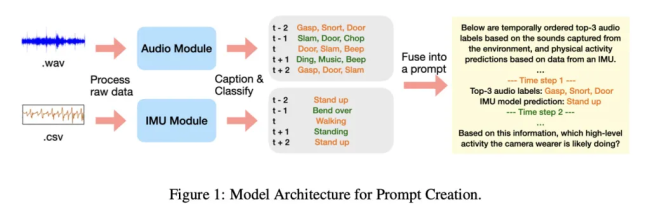
该技术的核心方法是通过小型模型生成的文本描述来分析数据。例如,音频模型会生成描述声音环境的文字(如“水流声”),而基于惯性测量单元的运动模型则会输出动作类型的预测文本。这种方式不仅保护了用户隐私,还展示了大语言模型在理解和融合多源文本信息以进行复杂推理的强大能力。
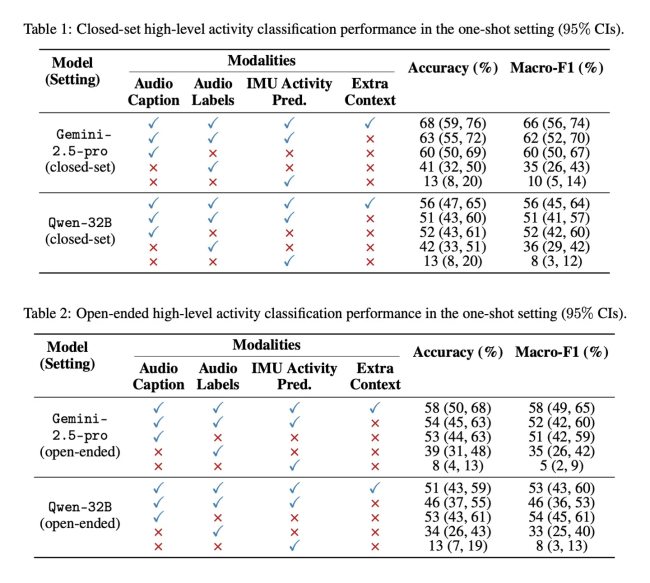
为了验证这种方法的有效性,研究团队使用了Ego4D数据集中的数千小时第一人称视角视频。他们从中选择了12种日常活动,包括吸尘、烹饪、洗碗、打篮球和举重等,每段样本时长为20秒。研究人员将小模型生成的文本描述输入给多个大语言模型,如谷歌的Gemini-2.5-pro和阿里的Qwen-32B,并测试其在零样本和单样本两种情况下的识别准确率。
测试结果显示,即使没有专门训练,大语言模型在活动识别任务中的表现也远超随机猜测水平,F1分数表现出色。当提供一个参考示例后,模型的准确度进一步提升。研究表明,利用大语言模型进行后期融合可以开发出强大的多模态应用,无需为特定场景开发专门模型,从而节省额外的内存和计算资源。苹果公司还公开了实验数据和代码,以便其他研究者复现和验证。
点击查看全文(剩余0%)